Over the course of the MIKELANGELO project, the package and application management has matured significantly. It was initially named MIKELANGELO Package Manager (MPM) to indicate its broader meaning. However, with progression of the project, it became harder to present the (exploitable) results under this name. Namely, we were introducing functionalities far outreaching the initial plan of plain package management, as defined in T4.3. We have therefore decided to extend the internal and external exploitation strategies and rebrand everything related to the deployment, management, reconfiguration of OSv-based unikernels under a single umbrella term - Lightweight Execution Environment Toolbox, LEET.
The work initially started mainly as a narrow WP4-specific (Guest Operating System) effort which was later expanded into cross work package effort, including WPs WP5 and WP6. At the very core of the application management are enhancements made to the Capstan[i] tool initially created by Cloudius Systems (now called Scylla DB). MIKELANGELO project introduced the concept of application packages along with their composition into self-contained runnable virtual machine images - unikernels. The package management then evolved integrating the OpenStack infrastructure services (including the WPs WP5 and WP6). This integration automated the deployment and management of unikernels to the users who are now able to use OSv-based applications independent of the deployment target: either locally or in the cloud (private or public OpenStack, Amazon EC2 and Google GCE). This has been initially achieved by implementing OpenStack provider for Capstan, and has later been replaced by integrating Capstan with the UniK[ii] tool. Integration with UniK gave significant visibility to the MIKELANGELO project in the unikernel community due to our collaboration with the upstream community.
Following subsections briefly describe current state of technologies dealing with the management of applications and presents high-level plans for the implementation of additional features until the end of the project. It consists of three parts: package management, cloud management and application orchestration.
Package management
As described in the previous deliverables (for example D4.5 - D4.5 OSv – Guest Operating System – intermediate version[iii]) the core of the package and application management tools of the MIKELANGELO project is based on Capstan. Package management and the ability to easily compose lightweight virtual machine images is the foundation of the overall application management in the MIKELANGELO project. To understand the core ideas behind package management in similar projects, a detailed analysis of existing tools for building and managing OSv-based virtual machine images, as well as some other unikernels like rumprun and MirageOS, has been performed. This led to the design of the initial architecture that has since then regularly been updated based on the new findings.
Because OSv allows reuse of precompiled libraries and applications, we wanted to design the architecture that revolves around prebuilt packages. This approach enables fast and simple composition of OSv images, removing the need for lengthy and error prone re-compilation of source code from the process. This architecture (Figure 1) was initially presented in D2.16[iv] and assumes three layers. The bottom layer represents the package repository storing application packages and their metadata. Because multiple repository providers are envisioned, an abstraction of a package repository is required. Primary package repository is an internal one (Local Repository in the diagram below) serving both as a temporary place for packages and virtual machines as well as local environment for execution of OSv unikernel.
The middle layer is the core of the package manager and provides a set of functionalities for building, validating and composing application packages and runnable virtual machine images. The topmost layer (Client) is a user-facing component that allows interaction with the remaining two layers. It is currently implemented as a command line interface (CLI).
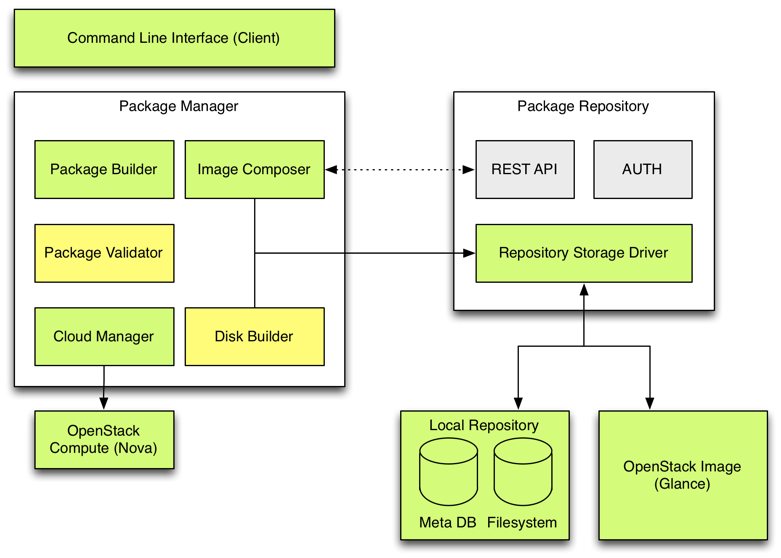 Figure 1. Initial architecture of the MIKELANGELO Package Management. Components marked with green color represent the main development focus.
Figure 1. Initial architecture of the MIKELANGELO Package Management. Components marked with green color represent the main development focus.
The diagram has been updated based on the current status, briefly presented in the following list:
- Initial version of Package Validator has been put in place. The main purpose of this component is to allow users to simply validate that the content of the required packages has been uploaded successfully. This involves the ability to run a simple application, pre-configured by the application manager, and testing against the expected results, namely it is a variant of unit and integration testing for application packages. In most cases the expected result is given as an expected output printed by the application. For example, in case of Node.js runtime package, the test could contain a simple JavaScript script, a run configuration specifying the exact command, and a text that is echoed by the script. OpenFOAM package could check that the invocation of the application indeed prints the name of the application solver used in the image.
- The cloud integration has been finalised. This included the integration with OpenStack image service as well as introduction of an abstract cloud manager and implementation for OpenStack provider. Together, this allows users to seamlessly deploy unikernels to OpenStack. This is reflected in the Openstack Nova and Glance components.
- Introduction of Disk Builder. This is current work in progress. This main goal of this component is to simplify the creation of ZFS disk images with specific content. By default, package manager composes a self-contained virtual machine image. However, it has become evident that end-users are typically interested in ability to have a single VM with just the core operating system and runtime environment, while the data, configuration and application scripts or binaries are provided through external volumes attached to the main instance. Since creating ZFS disk images is a rather cumbersome task, we started working on a component that would create such images of specified size and upload the required content (this would not include the kernel and accompanying libraries). Further details on the use of this component are outlined in the following subsections.
Further to these new enhancements, several updates to the existing requirements have also been made since the last release (MS4, M24). Below is a list of these updated requirements with their initial descriptions and the comments in their implementation and progress at MS5 and M30.
- Elimination of external dependencies (initial requirement). Capstan currently still relies on QEMU/KVM to compose and configure target virtual machine images. Currently this is not a mandatory requirement because users are still using Capstan in controlled environments, but the requirement is very important for external users.
M30 comments: This requirement has not been addressed yet and it has not been decided whether to proceed with the implementation. The main reason for this is that it has already been shown that these dependencies can easily be overcome by wrapping VM image composition into Docker containers. As task T4.3 is also responsible for the preparation of all relevant application packages (either used by MIKELANGELO use cases or are relevant to the broader communities) we have been automating the creation of the packages by wrapping build recipes into such containers allowing repeatable composition of all packages[v]. - Change of the underlying architecture (initial requirement). While we were implementing initial support for the chosen cloud provider, it became even more evident that the current architecture of the Capstan tool is not suitable for supporting alternative providers nor for providing services to external integrators (for example HPC integration). Because our main target so far was simplification from the end user’s perspective, we are planning to address this requirement in the next iteration.
M30 comments: Although we initially planned to expose the packaging mechanisms via API, we decided to keep the current architecture as the integration point is fairly small and can be handled easily with the approach. - Support for other guest operating systems (initial requirement). We have reevaluated this requirement with other potential systems, in particular unikernel systems. It became evident that there are significant differences in the way images are composed and/or compiled. Consequently, we are postponing this requirement for now. In D6.1 [6] we also mention a new project (Unik [19]) that has been trying to address this. We are following the project closely, and in discussions with the team behind it about potential collaboration.
M30 comments: This requirement has been covered by the integration of our tools into UniK project. Several attempts have been made to introduce other unikernels, however none of them proved suitable for the requirements of the MIKELANGELO project. The other unikernel approaches are too specific (not general purpose enough) or cannot be packaged as efficiently as OSv.
- Run-time options (initial requirement). This requirement is going to be addressed in the next iteration. It is important to allow users to work with OSv-based applications as if they were simple processes. During the comprehensive benchmarking of OSv applications it was observed on several occasions that it was impossible to understand the application without looking at the actual code. To this end we are going to expand the package metadata capabilities allowing package authors to provide reasonable documentation as well as the intended use cases (for example, default commands).
M30 comments: We have enhanced the ability to customise the run configuration by allowing default values of predefined configurations to be overridden from the command line interface.
- Finalise cloud integration. The initial target is to fully support OpenStack integration with more features available out-of-the-box. When we move from application packages, into runnable instances it is essential that their lifecycle can be managed from a central place. OSv applications are not typical in that the user can seamlessly connect to a remote machine to reconfigure it. Besides improving support for image and compute services, additional services are going to be integrated: networking and storage. This is going to be addressed in the next iteration.
M30 comments: This requirement has been addressed. Further details given in the following subsection.
- Abstraction of cloud provider. We believe that relying on a single cloud framework will limit the exploitation potential of the application packaging. To this end we are already planning to abstract the concept of a cloud provider. An implementation for Amazon AWS (and potentially OpenNebula) is going to be provided with this improvement.
M30 comments: Same as previous requirement.
- Package hub. Users are currently required to download and install the package repository locally. For the time being the number of packages and consequently the size of the repository is not large, so a central hub of all packages has not been necessary. With an increasing number of applications and packages, such a centralised hub will simplify the workflow acquiring only packages required by the end user.
M30 comments: We have introduced a package hub, publicly available at MIKELANGELO Package repository[vi]. The Capstan tool is extended with the querying and automatic downloading of required packages.
- Package usage description standardization. A package author has currently no standard means of providing package usage description where she could describe how to properly use the package. Package authors need a way to describe: (i) configuration files that must/can be provided, (ii) each configuration set purpose, (iii) parameters description and (iv) package limitations. In the future we should consider introducing a new file (e.g. /meta/doc.yaml) where package description would be stored.
M30 comments: This is work in progress. We have added support for run configuration documentation, however we regularly get feedback from internal or external users about missing built-in documentation system. The final release will thus include package documentation that will be exposed to package users.
- Package versioning. In report D4.5 we have also introduced a requirement for allowing more comprehensive versioning of the packages. Even though version has been introduced in the initial release of the tool, it was not used at all yet. We are still considering practical value for this as the current package repository is still maintainable.
In summary, the outlook for the last phase of the package management tool is to become even more user friendly and introduce some functionalities that have been identified while implementing the internal use cases as well as some other applications that are using unikernels. These requirements are frequently verified with the community and are now mainly targeting the application orchestration presented in the following sections.
Cloud Management
Management in cloud environment has already been implemented before milestone MS4. The main contribution in this area was the implementation of OpenStack connector into Capstan and UniK tools. Both implementations were presented in detail in report D4.5 (OSv - Guest Operating System – intermediate version)[vii]. This report also outlined some of the potential functionalities cloud management tools foresaw important, when bringing unikernels closer to the cloud management.
In the meantime the UniK project got significantly delayed because the whole team behind the project left Dell EMC. XLAB has discussed this transition and the effects it will have on the community with the UniK team lead. Albeit assuring the project will be preserved, it has now stagnated for several months. To this end we have decided to postpone the implementation of the described features. For completeness and in case the project is revived, we are listing these requirements next. The descriptions are taken from the aforementioned report D4.5 and updated with the current status.
Further integration of OpenStack provider. Should the UnIK project be revived, we plan to add support for block storage attachments. This will allow to bootstrap numerous small OSv-based unikernels and attach data and configurations on the fly[viii].
Use UniK Hub as a central repository for Capstan packages. UniK platform has introduced a central repository called UniK Hub where users are allowed to store their unikernels. Since Capstan is already providing it’s own centrally managed package repository, we are going to consider benefits of integrating that into UniK Hub. One potential problem with the UniK Hub is that it is dependent on the infrastructure provider (for example, OpenStack has a different hub than VMware and Amazon Web Services). Since Capstan builds images that can be suited to other providers, it may be better to focus on improving Capstan’s package repository capabilities than integrating it with a Hub that may not exploit all of its potential.
Support cloud orchestration templates. This requirement discussed the ability to allow application orchestration directly from the UniK tool. We are going to abandon this approach in favour of enhancing the application orchestration as part of the Kubernetes integration. We believe this will enable much better reuse of unikernel-based applications. Sheer size of the Kubernetes community also guarantees that our integration efforts will actually be used by a broader community.
Application Orchestration
Orchestration of OSv-based unikernels is one of the challenges that hasn’t been addressed extensively in MIKELANGELO until now. The application management focused on being able to simplify the creation of self-contained virtual machines executing a single process and deploying them to the cloud. Limited efforts towards orchestrating the services were made in experiments using OpenStack Heat[ix] orchestration. Albeit working, it proved a bit cumbersome and very specific to the underlying infrastructure vendor. In collaboration with DICE[x] H2020 project we analysed Cloudify[xi] project which abstracts the underlying orchestration engine by using the TOSCA[xii] standard. At the time this meeting was held (~M27) Cloudify focused almost exclusively on OpenStack as well so we again decided not to go along this path.
Even in the initial project proposal, three years ago, we stated that using unikernels should be as simple as using containers. Therefore, we were also closely following the Kubernetes[xiii] project throughout the entire MIKELANGELO project. The Kubernetes system gives its users power over deployment, scaling and management of containers (for example based on Docker). Using its open format, it allows one to configure the whole application stack that is automatically deployed and configured on the fly. Each service is deployed in a separate container and all are properly interconnected to be able to exchange information.
Earlier in this year (2017) Mirantis published an initial (pre-alpha) release of a plugin for Kubernetes that provisions virtual machines based on Kubernetes specification. This plugin, Virtlet[xiv], extends Kubernetes Container Runtime Interface (CRI)[xv] and ensures that service specification is provisioned as a virtual machine just as if it were a container. This offers tremendous power to the users who are now able to choose the optimal deployment target through the same well-known interface. For example, an application can consist of an Oracle Database and a set of services interacting with the database and with each other. To achieve optimal performance and isolation, the database should be deployed into a dedicated virtual machine, while the services themselves can be deployed as containers. Virtlet allows for such a mix through the same interface, offered by Kubernetes.
MIKELANGELO has been in close contact with Mirantis from the very beginning to discuss the plans and potential collaboration. The initial plan was to evaluate the technology to assess whether it is useful in the context of unikernels. To this end, we have extended the microservice application[xvi] we have been developing. This application serves as a showcase for the whole application package management stack. Based on this, MIKELANGELO became the first external source code contributor to the Virtlet project. MIKELANGELO was also invited to present the results in the official Kubernetes sig-node meeting[xvii]. This contribution exposes virtual machine logs to Kubernetes management layer. The reasoning behind the contribution lies in the fact that contrary to the Linux guests, OSv does not have the ability to connect to the machine and examine the logs. Virtlet provided access to the console of the VM, however this does not contain the log that was written before the console has been opened. It furthermore provides plain text logs which are not understood by Kubernetes and are thus not exposed to the users through its interfaces.
The following figure shows a schema of the logging contribution that we have designed and implemented. The main goal was to be completely compliant with the existing architecture while keeping the logging independent of the other components of Kubernetes and Virtlet.
 Figure 2: Logging schema introduced into Kubernetes Virtlet.
Figure 2: Logging schema introduced into Kubernetes Virtlet.
In case logging is enabled, the virtual machines are configured to redirect all messages that are printed to the serial console into a log file stored in /var/log/virtlet/vms. This directory is then mounted into a special virtlet-log container, which is responsible for monitoring for changes in this directory. Whenever a new log file is identified, a separate log worker is created, which will then follow the log file for changes and convert it to a log file compliant with Kubernetes/Docker (this file basically contains a single JSON per line, consisting of a timestamp and the actual log message).
Albeit this contribution is rather basic, it serves as the foundation of two important pillars. First, by exposing logs to the end users, it allows seamless execution of OSv-based services on top of Kubernetes. Users no longer need to build their instances for debugging purposes as they will get all the necessary information directly from the management layer.
Second, it has positioned MIKELANGELO project as an external contribution to an open source project, sponsored by one of the biggest open source contributors to OpenStack and Kubernetes. This will also benefit the Virtlet project when considering the incubation into the Kubernetes ecosystem.
The plan for the remaining phases of the project is to bridge more gaps between the containers, Linux-based guests and OSv-based guests. The following is the list of features that have been identified so far, but as the integration is quite new, this might change to address the crucial needs.
Enable unikernel contextualisation. The Kubernetes Virtlet still relies only on the NoCloud[xviii] cloud-init data source. Albeit OSv has added support for NoCloud, it supports a custom exchange format. The decision was made while adding contextualisation support into HPC integration where it was important only to have an integration possible. With Virtlet, it is now required to adhere the specification and thus support the meta- and user-data to be provided as ISO9660 volume. At the time of writing this report, alternatives are being investigated, e.g. to instead integrate OSv’s format into Virtlet, however this might over complicate the integration. One of the main reasons why being able to use contextualisation features from Kubernetes is vital, is the ability to set the command to run within OSv instance. At the moment, Kubernetes is only able to provision unikernel as it is meaning that each service has to have its own VM image even if they differ in nothing but boot command. With full cloud-init support, however, a single VM image with several run configuration will be required.
Volume attachments support. In containers, various custom data (e.g. configuration, data, scripts) are frequently exported to the container as external volumes, attached to them. Virtlet is already adding support for volume attachments, however in case of OSv, getting the volume to work properly with its Virtual File System is not trivial. This is because ZFS is the only local filesystem known to OSv. Integrating additional filesystems may be too complex, so we are considering adding additional VM composition phase. This would allow one to build OSv-compliant VM images in advance and attach them dynamically to the deployed instances. Reconfiguration, data initialisation and business logic implementation would thus be separated from the main unikernel containing only the enabling runtime environment.
Application Packages
The following is the list of pre-built application packages. Some packages are merely updated to the latest version, while others are completely new. The packages are hosted in a public MIKELANGELO package repository[xix]. These packages can be used directly using the tools from LEET.
OSv launcher (OSv kernel)
A bootable image containing the OSv kernel and the tools required to compose the target application image. This image is inherently included in all application images whenever they are composed. A bootstrap package accompanies the launcher further providing system-wide libraries that are required for proper operation of the OSv-based VM (for example, a library for the ZFS file-system [15]).
HTTP Server
The package contains the REST management API for the OSv operating system. It allows users to query and control all kinds of information about the OS.
Command Line Interface (CLI)
Provides a simple interactive shell for OSv virtual machines, mostly useful for debugging purposes. The CLI primarily offers a user-friendly interface to the HTTP server. Therefore, it automatically includes the HTTP Server package.
Open MPI[xx]
This package contains libraries and tools required to run MPI-based applications. It is intended as a supporting package for HPC applications that need the MPI infrastructure: either just Open MPI libraries or also the mpirun command for launching parallel workloads.
OpenFOAM Core[xxi]
This package includes the base libraries, tools and supporting files that are required by arbitrary applications based on OpenFOAM toolkit.
OpenFOAM simpleFoam
OpenFOAM solver application, used extensively by the Aerodynamics use case. The package only contains a single binary (application) and references the core package above for the remaining functionalities. This solver is has been validated and evaluated most thoroughly in the MIKELANGELO project.
OpenFOAM solvers
OpenFOAM comes with additional solvers that can be used in different simulation scenarios. As part of our efforts, we have created packages for the following solvers[xxii]: pimpleFoam, pisoFoam, porousSimpleFoam, potentialFoam, rhoporousSimpleFoam and rhoSimpleFoam.
Java[xxiii]
The package contains an entire Java Virtual Machine and supporting tools for running arbitrary applications on top of OSv. It has been successfully tested with several applications such as Cassandra, Hadoop HDFS and Apache Storm. Different versions as well as different Java profiles are used to pre-package Java runtime suitable for as many deployment scenarios as possible.
Node.js[xxiv]
Node.js is another popular runtime environment used for backend development. It allows execution of JavaScript code making it ideal for lightweight services, microservices. It has also been used extensively in so called serverless architectures that are becoming widely popular with all public cloud providers. Several versions of Node are available, both for the 4.x and 6.x series which are provided as LTS (Long Term Support) versions. Users of these packages can deploy any of their existing Node.js applications and run them without any changes. A three part blog post[xxv] has been written to explain the use of this package in a simplistic microservice-like application.
Cloud-init[xxvi]
This package allows contextualisation of running instances, for example setting the hostname of the VM and creating files with specific content. If this package is included in the application image, it will, immediately upon start, look for available data sources used in common cloud environments:
- Amazon EC2 [24]: used by Amazon AWS as well as default OpenStack. It provides a metadata service that cloud-init [25, 26] can access at a specific IP address.
- Google Compute Engine [27]: used in cloud, provided by Google
- No cloud-like data source [28]: in this case user data is attached to the target VM as a dedicated disk image from where the cloud-init will read and load necessary data.
Hadoop HDFS[xxvii]
Hadoop HDFS is one of the core components of the big data application enabling practically unlimited distributed storage. It is used in many applications based on the Hadoop/Apache big data ecosystem. It is a Java-based application that inherently uses subprocesses for various internal tasks. This package was chosen to demonstrate the required steps for patching such applications and making them compatible with the OSv unikernel. Albeit HDFS works in OSv it has been shown that it lacks performance of Linux-based systems in report D6.3[xxviii]. The performance issues have mainly been attributed to the virtual file system (VFS) and specifically the implementation of the ZFS file system in OSv.
Apache Storm[xxix]
Experiments with Apache Storm have started to complement the HDFS packages. Storm is used for processing Streams of data. Because of its architecture where workers get allocated by a master entity, it is an ideal example of the application that could benefit from the lightweight nature of OSv-based unikernels. Spawning additional OSv workers should be significantly faster than requesting new Linux virtual machines. One of the issues with Storm is that these workers are created by forking and launching a separate Java virtual machines (JVM) which makes them impractical for OSv. Since Storm also started losing in popularity we focused more on Apache Spark.
Apache Spark[xxx]
Apache Spark is one of the most popular tools for working with large amounts of data. Although it was initially designed for batch processing, Spark Streaming removes any necessity for Apache Storm. Similarly to Storm, Spark creates new workers by bootstrapping additional JVMs, however it does this by the support of the resource manager. This simplifies the integration and makes it significantly more transparent. To this end, we are working extensively in making the Spark package suitable for OSv.
Capabilities of the Application Packages
The aforementioned packages have already been used in various configurations. The Aerodynamics use case have extensively used the OpenFOAM simpleFoam package along with the Open MPI to support parallelism. All packages have been tested in local environment and in the cloud, while some have also been deployed in HPC environment (MPI, OpenFOAM, cloud-init).
The following are the functionalities of application packages that have been presented in the previous version of the package report. These descriptions provide updates as well as plans for those that haven’t been addressed yet.
- Cloud-init module must support attaching of network shares. Standard cloud-init supports the mounts option allowing users to provide specific volumes and network shares to be mounted into the target VM automatically upon start. For HPC applications it is mandatory that such support is integrated into OSv’s cloud-init module allowing execution of experiments based on external data.
Update: cloud-init module has been extended with the ability to attach one or more additional volumes. Only NFS backends are supported as no other requirements have been made. The structure of the mount command adheres the specification of the cloud-init.
- Customisable Open MPI application package. The existing Open MPI application package must be extended to support additional configuration options suitable for wider ranges of MPI applications.
Update: MPI package is exposing the functionalities of the Open MPI commands and has already been validated by the Aerodynamics and Bones use cases.
- Support for mpirun HPC use cases in MIKELANGELO project (Aerodynamics and Cancellous Bones) rely heavily on the MPI for distribution of workload and synchronisation between individual processes. mpirun is the main entry point for these two applications. Because the OSv-based infrastructure is fundamentally different from the one in a typical HPC setting, the MPI application package must ensure transparent use of virtualised workloads running in OSv. This requirement is also fundamental for external exploitation in HPC applications.
Update: mpirun command has been updated to work exactly the same as in standard environment. The only difference is the addition of specific communication channel that is required because MPI workers are configured through their REST APIs instead of being invoked through SSH.
- Additional use-case specific pre-built application packages. This is a placeholder requirement for all the remaining applications that will be running OSv-enabled application images, in particular for the Big-data and Bones use cases. All of these packages need to be prepared in a way suitable for a broader audience. This will allow reuse of composable, pre-packaged applications, and seamless deployment in target environments.
Update: no additional packages have been created specifically for the use cases. Hadoop HDFS has already been created and Apache Spark is being investigated.
- Multiple runtime environments. Besides Java we are also interested in other runtime environments, such as Node.js, Go and Python. Node.js has already been tested, but not provided as an application package. Other environments are going to be evaluated and integrated accordingly. This requirement has not been expressed by any of the use cases. However, following discussions with potential external stakeholders it is vital that they are supported with little or no modifications required to user’s applications. Very minor and mostly boilerplate changes should be required at most.
Update: as described above, LTS versions of Node.js are now available as pre-built packages. Golang support for OSv has been tested, however not brought to a production-ready package so it was not made available as a package yet.
We will continue to update existing and create new packages as they become available or interesting enough for this line of work. Main focus will continue to be on the packages related to the use cases of the MIKELANGELO project. However, to improve chances for exploitation and dissemination, other packages may be used as well.
[i] Capstan homepage http://osv.io/capstan/
[ii] UniK Github repository, https://github.com/cf-unik/unik
[iii] D4.5 OSv – Guest Operating System – intermediate version, https://www.mikelangelo-project.eu/wp-content/uploads/2017/01/MIKELANGELO-WP4.5-SCYLLA-v2.0.pdf
[iv] D2.16 The First OSv Guest Operating System MIKELANGELO Architecture, http://www.mikelangelo-project.eu/deliverable-d2-16/
[v] Capstan Package Automation, https://github.com/mikelangelo-project/capstan-packages
[vi] MIKELANGELO Capstan Package Repository, https://mikelangelo-capstan.s3.amazonaws.com
[vii] Report D4.5, OSv - Guest Operating System – intermediate version, https://www.mikelangelo-project.eu/wp-content/uploads/2017/01/MIKELANGELO-WP4.5-SCYLLA-v2.0.pdf
[viii] Note: similar approach will be described in the next section where we discuss the application orchestration.
[ix] OpenStack Heat, https://wiki.openstack.org/wiki/Heat
[x] DICE project home page, http://www.dice-h2020.eu
[xi] Cloudify home page, http://cloudify.co
[xii] OASIS Tosca standard, http://docs.oasis-open.org/tosca/TOSCA/v1.0/os/TOSCA-v1.0-os.html
[xiii] Kubernetes home page, https://kubernetes.io
[xiv] Mirantis Virtlet plugin source, https://github.com/mirantis/virtlet
[xv] Kubernetes Container Runtime Interface, http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
[xvi] MIKELANGELO OSv Microservice Showcase Application, https://github.com/mikelangelo-project/osv-microservice-demo
[xvii] Kubernetes sig-node community, https://github.com/kubernetes/community/tree/master/sig-node
[xviii] NoCloud cloud-init documentation, http://cloudinit.readthedocs.io/en/latest/topics/datasources/nocloud.html
[xx] Open MPI Home page, https://www.open-mpi.org.
[xxi] OpenFOAM Home page, http://www.openfoam.com.
[xxii] Standard OpenFOAM Solvers, http://www.openfoam.com/documentation/user-guide/standard-solvers.php
[xxiii] Java Home page, https://java.com/en/.
[xxiv] Node.js Home page, https://nodejs.org/en/.
[xxv] Microservice demo application blog post, https://www.mikelangelo-project.eu/2017/05/the-microservice-demo-application-introduction/
[xxvi] Cloud-init documentation, https://cloudinit.readthedocs.io/en/latest/.
[xxvii] Hadoop HDFS, https://hortonworks.com/apache/hdfs/.
[xxviii] https://www.mikelangelo-project.eu/wp-content/uploads/2017/01/MIKELANGELO-WP6.3-GWDG-v2.0.pdf
[xxix] Apache Storm, http://storm.apache.org.
[xxx] Apache Spark, http://spark.apache.org.
