Introduction
As we noted above, the primary goal of OSv is to run existing Linux software, because most MIKELANGELO use cases required running existing code. Today’s Linux APIs - POSIX system calls, socket API, etc. - were formed by decades of Unix and Linux legacy, and some aspects of them are inherently inefficient. OSv can improve the performance of applications which use these APIs, but not dramatically. So our second goal in the development of the guest operating system was to propose new APIs which will offer new applications dramatically better performance than unmodified Linux applications - provided that the application is rewritten to use these new APIs,
In the research paper “OSv — Optimizing the Operating System for Virtual Machines”[[i]], one of the benchmarks used was Memcached, a popular cloud application used for caching of frequently requested objects to lower the load on slower database servers. Memcached demonstrated how an unmodified network application can run faster on OSv than it does on Linux - a 22% speedup was reported in the paper.
22% is a nice speedup that we get just by replacing Linux in the guest by OSv, without modifying the application at all. But we wanted to understand if there is something we could do to get significantly higher performance. When we profiled memcached on OSv, we quickly discovered two performance bottlenecks:
- Inefficiencies inherent in the Posix API, so OSv cannot avoid them and still remain POSIX compatible: For example, in one benchmark we noticed that 20% of the memcached runtime was locking and unlocking mutexes - almost always uncontended. For every packet we send or receive, we lock and unlock more than a dozen mutexes. Part of OSv’s performance advantage over Linux is that OSv uses a “netchannel” design for the network stack reducing locks (see the previous section), but we still have too many of them, and the Posix API forces us to leave many of them: For example, the Posix API allows many threads to use the same socket, allows many threads to modify the list of file descriptors, to poll the same file descriptors - so all these critical operations involve locks, that we cannot avoid. The socket API is also synchronous, meaning that when a send() returns the caller is allowed to modify the buffer, which forces the network code in OSv to not be zero-copy.
- Unscalable application design: It is not easy to write an application to scale linearly in the number of cores in a multi-core machine, and many applications that work well on one or two cores, scale very badly to many cores. For example memcached keeps some global statistics (e.g., the number of requests served) and updates it under a lock - which becomes a major bottleneck when the number of cores grow. What might seem like an acceptable solution - lock-free atomic variables - is also not scalable, because while no mutex is involved, atomic operations, and the cache line bounces (as different CPUs read and write the same variable), both become slower as the number of cores increase. So writing a really scalable application - one which can run on (for example) 64 cores and run close to 64 times faster than it does on a single core - is a big challenge and most applications are not as scalable as they should be - which will become more and more noticeable as the number of cores per machine continues to increase.
In the aforementioned OSv paper, we tried an experiment to quantify the first effect - the inefficiency of the Posix API. The subset of memcached needed for the benchmark was very simple: a request is a single packet (UDP), containing a “GET” or “PUT” command, and the result is a single UDP packet as well. So we implemented in OSv a simple “packet filter” API: every incoming ethernet packet gets processed by a function (memcached’s hash-table lookup) which immediately creates the response packet. There is no additional network stack, no locks or atomic operations (we ran this on a single CPU), no file descriptors, etc. The performance of this implementation was an impressive 4 times better than the original memcached server.
But while the simple “packet filter” API was useful for the trivial UDP memcached, it was not useful for implementing more complex applications, for example applications which are asynchronous (cannot generate a response immediately from one request packet), use TCP or need to use multiple cores. Fast “packet filter”-like APIs are already quite commonly used (DPDK is a popular example) and are excellent to implement routers and similar packet-processing software; But they are not really helpful if you try to write a complex, highly-asynchronous network applications of the kind that is often used on the cloud - such as a NoSQL database, HTTP server, search engine, and so on.
For the MIKELANGELO project, we set out to design a new API which could answer both above requirements: An API which new applications can use to achieve optimal performance (i.e., the same level of performance achieved by the “packet filtering API” implementation), while at the same time allows the creation of complex real-life applications: The result of this design is Seastar:
- Seastar is a C++14 library, which can be used on both OSv and Linux. Because Seastar bypasses the kernel for most things, we do not expect additional speed improvements by running it on OSv - though some of OSv’s other advantages (such as image size and boot time) may still be relevant.
- Seastar is designed for the needs of complex asynchronous server applications of the type common on the cloud - e.g., NoSQL databases, HTTP servers, etc. Here “asynchronous” means that a request usually triggers a cascade of events (disk reads, communication with other nodes, etc.) and only at a later time can the reply be composed.
- Seastar provides the application the mechanisms it needs to solve both performance bottlenecks mentioned at the top of this section: Achieve optimal efficiency on one core, as well as scalability in the number of cores. We’ll explain how Seastar does this below.
- Seastar can bypass the legacy kernel APIs, e.g., it can directly access the network card directly using DPDK. Seastar provides a full TCP/IP stack (which DPDK does not).
We’ve reimplemented memcached using Seastar, and measured 2 to 4-fold performance improvement over the original memcached as well as near-perfect scalability to 32 cores (something which the “packet filter” implementation couldn’t do). Figure below for more details.
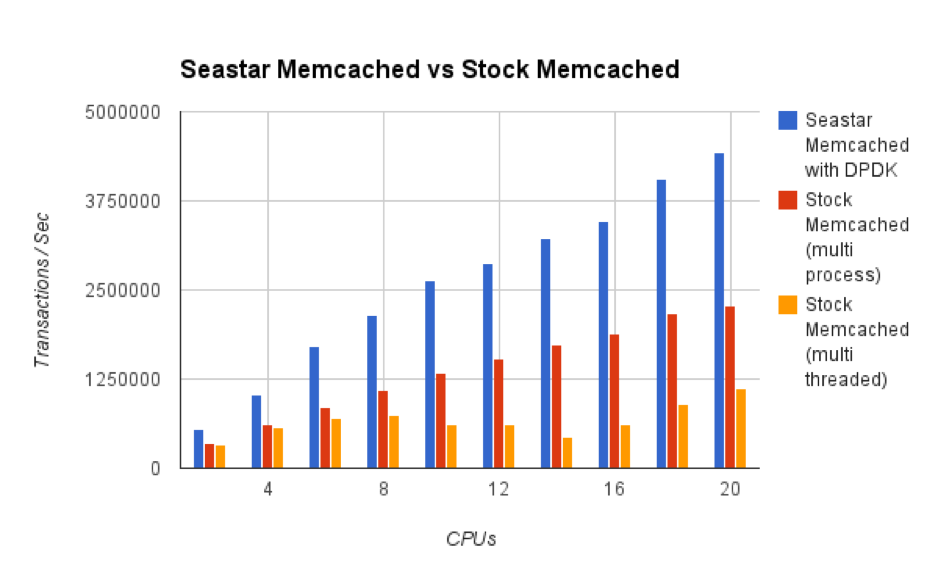 Figure: Performance of stock memcached (orange) vs Seastar reimplementation of memcached (blue), using TCP and the memaslap[[ii]] workload generator - for varying number of cores The red bars show a non-standard memcached deployment using multiple separate memcached processes (instead of one memcached with multiple threads); Such a run is partially share-nothing (the separate processes do not share memory or locks) so performance is better than the threaded server, but still the kernel and network stack is shared so performance is not as good as with Seastar.
Figure: Performance of stock memcached (orange) vs Seastar reimplementation of memcached (blue), using TCP and the memaslap[[ii]] workload generator - for varying number of cores The red bars show a non-standard memcached deployment using multiple separate memcached processes (instead of one memcached with multiple threads); Such a run is partially share-nothing (the separate processes do not share memory or locks) so performance is better than the threaded server, but still the kernel and network stack is shared so performance is not as good as with Seastar.
Applications that want to use Seastar will need to be rewritten to use its new (and very different) APIs. This requires significant investment, but also comes with significant rewards: The creator of the Seastar library, ScyllaDB, spent the last two years reimplementing the popular Cassandra distributed database in C++ and Seastar, and the result, “Scylla” (which, like Seastar and OSv, is released as open source[[iii]]), has much higher throughput than Cassandra: Independent benchmarks[[iv]] by Samsung showed Scylla to have between 10 to 37 times higher throughput than Cassandra on a cluster of 24-core machines in different workloads, In fact, the Scylla distributed database performs so well that it has become ScyllaDB’s main product, making the company highly dependent on Seastar’s exploitation. For this reason, ScylllaDB has been investing into Seastar additional efforts beyond what is being funded by the MIKELANGELO project, and plans to continue developing Seastar even after the project ends.
We use Scylla, the Seastar-based reimplementation of Cassandra, in the “Cloud Bursting” use case. But our goal is for Seastar to be a general-purpose APIs which will be useful to many kinds of asynchronous server applications, which are often run on the cloud. As such, we are making an effort of providing a rich, well-balanced, and well documented API, and also writing a tutorial on writing Seastar applications (a draft of which was already included in D4.4 and D4.5). At the time of this writing, we know of at least two other companies besides ScyllaDB which based their product on Seastar, and more are considering doing this.
Seastar architecture
How can an application designed to use Seastar be so much faster than one using more traditional APIs such as threads, shared memory and sockets? The short answer is that modern computer architecture has several performance traps that are easy to fall into, and Seastar ensures that you don’t by using the following architecture:
- Sharded (“share nothing”) design:
Modern multi-core machines have shared memory, but using it incorrectly can drastically reduce an application’s performance: Locks are very slow, and so are processor-provided “lock-free” atomic operations and memory fences. Reading and writing the same memory object from different cores significantly slows down processing compared to one core finding the object in its cache (this phenomenon is known as “cache line bouncing”). All of these slow operations already hurt one-core performance, but get progressively slower as the number of cores increases, so it also hurts the scaling of the application to many cores.
Moreover, as the number of cores increases, multi-core machines inevitably become multi-socket, and we start seeing NUMA (non-uniform memory access) issues. I.e., some cores are closer to some parts of memory - and accessing the “far” part of memory can be significantly slower.
So Seastar applications use a share-nothing design: Each core is responsible for a part (a “shard”) of the data, and does not access other cores’ data directly - if two cores wish to communicate, they do so through message passing APIs that Seastar provides (internally, this message passing uses the shared memory capabilities provided by the CPU).
When a Seastar application starts on N cores, the available memory is divided into N sections and each core is assigned a different section (taking NUMA into account in this division of memory, of course). When code on a core allocates memory (with malloc(), C++’s new, etc.), it gets memory from this core’s memory section, and only this core is supposed to use it.
- Futures and continuations, not threads:
For more than a decade, it has been widely acknowledged that high-performance server applications cannot use a thread per connection, as those impose higher memory consumption (thread stacks are big) and significant context switch overheads. Instead, the application should use just a few threads (ideally, just one thread per core) which each handles many connections. Such a thread usually runs an “event loop” which waits for new events on its assigned connections (e.g., incoming request, disk operation completed, etc.) and processes them. However, writing such “event driven” applications is traditionally very difficult because the programmer needs to carefully track the complex state of ongoing connections to understand what each new event means, and what needs to be done next.
Seastar applications also run just one thread per core. Seastar implements the futures and continuations API for asynchronous programming, which makes it easier (compared to classic event-loop programming) to write very complex applications with just a single thread per core. A future is returned by an asynchronous function, and will eventually be fulfilled (become ready), at which point a continuation, a piece of non-blocking code, can be run. The continuations are C++ lambdas, anonymous functions which can capture state from the enclosing code, making it easy to track what a complex cascade of continuations is doing. We explain Seastar’s futures and continuations in more detail below.
The future/continuation programming model is not new and has been used before in various application frameworks (e.g., Node.js), but before Seastar, it was only partially implemented by the C++14 standard (std::future). Moreover, Seastar’s implementation of futures are much more efficient than std::future because Seastar’s implementation uses less memory allocation, and no locks or atomic operations: A future and its continuation belong to one particular core, thanks to Seastar’s sharded design.
- Asynchronous disk I/O
Continuations cannot make blocking OS calls, or the entire core will wait and do nothing. So Seastar uses the kernel’s AIO (“asynchronous I/O”) mechanisms instead of the traditional Unix blocking disk IO APIs. With AIO, a continuation only starts a disk operation, and returns a future which becomes available when the operation finally completes.
Asynchronous I/O is important for performance of applications which use the disk, and not just the network: A popular alternative (used in, for example, Apache Cassandra) is to use a pool of threads processing connections, so when one thread blocks on a disk access, a different thread gets to run and the core doesn’t remain idle. However, as explained above, using multiple threads has large performance overheads, especially in an application (like Cassandra) which may need to do numerous concurrent disk accesses. With modern SSD disk hardware, concurrent non-sequential disk I/O is no longer a bottleneck (as it was with spinning disks and their slow seek times), so the programming framework should not make it one.
- Userspace network stack
Seastar can optionally bypass the kernel’s (Linux’s or OSv’s) network stack and all its inherent inefficiencies like locks, by providing its own network stack:
Seastar accesses the underlying network card directly, using either DPDK (on Linux or OSv) or virtio (only supported on OSv). On top of that, it provides a full-featured TCP/IP network stack, which is itself written in Seastar (futures and continuations) and correspondingly does not use any locks, and instead divides the connections among the cores; Once a connection is assigned to a core, only this core may use it. The connection will only be moved to a different core if the application decides to do so explicitly).
Importantly, Seastar’s network stack supports multiqueue network cards and RSS (receive-side steering), so the different cores can send and receive packets independently of each other without the need for locks and without creating bottlenecks like a single core receiving all packets. When the hardware’s number of queues is limited below the number of available cores, Seastar also uses software RSS - i.e., some of the cores receive packets and forward them to other cores.
Additional Seastar components
Above we explained a few key parts of Seastar’s architecture, including its sharded design, futures and continuations, asynchronous disk I/O, and the user-space TCP/IP stack. But Seastar includes many more components, which we will briefly survey now. Work on polishing and documenting all of these components is ongoing, but the CPU scheduler will be receiving particular attention and improvements in the upcoming months in an effort to continue reducing the latency of ScyllaDB and other Seastar applications.
- Reactor: The Seastar “reactor” is Seastar’s main event loop; A reactor thread runs on each of the cores dedicated to the application, polls for new events (network activity, completed disk I/O, expired timers, and communication between cores) to resolve the relevant futures, and runs continuations on the ready queue (continuations attached to futures that have been resolved).
The Seastar reactor is not preemptive, meaning that each continuation runs to completion or until it voluntarily ends. This means that application code in each continuation does not need to worry about concurrent access to data - nothing can run on this core in parallel to the running continuation, and the continuations on other cores cannot access this core’s memory anyway (thanks to the share-nothing design, more on that below).
When idle, the reactor can either continue polling or go to sleep; The former approach improves latency, but the latter allows lower power consumption. The user can choose one of these options, or let Seastar choose between them automatically based on the load.
In any case, Seastar applications are meant to monopolize the CPU cores they are given, and not time-share them with other applications. This comes naturally in the cloud, where the VM runs a single application anyway.
- Memory allocation: Seastar divides the total amount of memory given to it between the different cores (reactor threads). Seastar is aware of the NUMA configuration, and gives each core a chunk of memory it can most efficiently access. The C library’s malloc() (and related standard C and C++ allocator functions) is overridden by Seastar’s own memory allocator, which allocates memory from the current shard’s memory area. Memory allocated on one shard may only be used by the same shard. Seastar has limited facilities for allowing one shard to use memory allocated by another shard, but generally these are not to be used, and shards should communicate via explicit message passing as described below.
- Message passing between shards: Seastar applications are sharded, or share-nothing, and shards do not normally read from each other’s memory because, as we already explained, doing that requires slow locks, memory barriers and cache-line bouncing. Instead, when two shards want to communicate, they do this via explicit message passing, implemented internally over shared memory. The message passing API allows running a piece of code (a lambda) on a remote shard. This code is run by the reactor running on the remote shard - as explained above, without risk of parallel execution of continuations.
- Log structured allocator (LSA): Seastar’s malloc()/free() described above is more-or-less identical to the traditional one, except the fact that it uses a different memory pool for each core. Perhaps the biggest downside of the malloc()/free() API is that it causes fragmentation - it is possible (and after a long run, fairly likely) that allocating and freeing of small objects will prevent allocation of a larger object, even though we might still have plenty of unused memory. Because the user of the allocated object may save pointers to them, the memory allocator is not allowed to move them around to fix fragmentation.
Garbage Collection is a common way to solve this problem, because part of the work of a garbage-collector is to compact (i.e., move) the objects in memory, so it can free up large contiguous areas of memory. However, GC comes with an additional anti-feature: It needs to search where the garbage (freed) objects are, and this search is where most of GC’s disadvantages come from (e.g., pauses, and need for plenty of spare memory).
Seastar’s LSA (log-structured allocator) aims to be the best of both-worlds: Like malloc()/free(), memory is explicitly allocated and freed (in modern C++ style, automatically by object construction/destruction), so we always know exactly which memory is free. But additionally, LSA memory may move around (or automatically be evicted), and the LSA APIs allow tracking where an object moved, or prevent movements temporarily.
- I/O scheduler: One of the key requirements that arose in the “Cloud Bursting” use case was to ensure that performance does not deteriorate significantly during a period of cluster growth. When a Cassandra cluster grows, the new nodes need to copy existing data from the old nodes, so now the old nodes use their disk for both streaming data to new nodes, and for serving ordinary requests. It becomes crucial to control the division of the available disk bandwidth between these two uses. The I/O scheduler allows the application to tag each disk access with an I/O class, for example a “user request” vs. “streaming to new node”, and can control the percentage of disk bandwidth devoted to each class.
- I/O tune: Seastar’s disk API is completely asynchronous and future-based just like everything else in Seastar. This means that an application can start a million requests (read or write) to disk almost concurrently, and then run some continuation when each request concludes. However, real disks as well as layers above them (like RAID controllers and the operating system), cannot actually perform a million requests in parallel; If you send too many, some will be performed immediately and some will be queued in some queue invisible to Seastar. This queuing means that the last queued request will suffer huge latency. But more importantly, it means that we can no longer ensure the desired I/O scheduling, because when a new high-priority request comes in, we cannot put it in front of all the requests which are already queued in the OS’s or hardware’s queues, beyond Seastar’s control.
So clearly Seastar should not send too many parallel requests to the disk, and it should maintain and control an input queue by itself. But how many parallel requests should it send to the lower layers? If we send too few parallel requests, we might miss out on the disk’s inherent parallelism: Modern SSDs, as well as RAID setups, can actually perform many requests in parallel, so that sending them too few parallel requests will reduce the maximum throughput we can get in those setups.
Therefore we developed “IOtune”, a tool that runs on the intended machine, tries to do disk I/O with various levels of parallelism, and discovers the optimal parallelism. The optimal parallelism is the one where we get the highest possible throughput, without significantly increasing the latency. This is the amount of parallelism which the disk hardware (and RAID controllers, etc.) can really support and really perform in parallel. After discovering the optimal parallelism, IOtune writes this information to a configuration file, and the Seastar application later reads it for optimal performance of Seastar’s disk I/O.
- CPU scheduler: The I/O scheduling feature which we described above goes a long way to ensure that when the system needs to run two unrelated tasks (such as the data-streaming and the request-handling mentioned above) one of them does not monopolize all the resources. However, in some cases ScyllaDB has work in which there is very little disk I/O but significant computation - and in such cases the I/O scheduler is not enough and we need an actual CPU scheduler.
We explained above how the reactor has a queue of ready continuations which need to run; With the CPU scheduler, we have several of these queues, each belonging to a different “scheduling group”. The application author tags continuations as belonging to a particular scheduling group, and the reactor’s CPU scheduler chooses which scheduling group’s continuation(s) to run next, while considering fairness and latency requirements. The latency requirements are especially important, and are one of Seastar’s strong points: For example, we do not want continuations belonging to some background operation to run for 100ms, while continuations belonging to client request handling just wait (and incur a large user-visible latency).
- SEDA: Somewhat related to the CPU scheduler is Seastar’s support for batching of continuations inspired by the well-known SEDA (“staged execution event-driven architecture”) concept:
The fact that Seastar works with short continuations instead of coarse threads contributes to its higher throughput and lower latency, but introduces a new problem: The CPU constantly jumps between different pieces of code, the instruction cache is not large enough to fit them all, and execution speed (instructions per cycle) becomes suboptimal. To solve this, Seastar provides a mechanism whereby the application can ask to batch certain continuations together. For example - instead of running a certain continuation immediately, Seastar might wait until 100 instances of the same continuation are ready - and then run them one after another. An important part of this Seastar mechanism is that it ensures the latency required by the application: A continuation will not be delayed for batching by more than that desired latency, and, conversely - we cannot collect so many continuations into one batch so that when we run this batch, everything hangs for too long a time. The end result of Seastar’s SEDA mechanism is a delicate balance between high execution efficiency (high instructions/cycle) and low latencies.
- TLS (transport layer security): In addition to providing an asynchronous, zero-copy, interface to the TCP/IP protocol suite, Seastar also gives the same interface to secure TLS (formerly known as SSL) connections.
- RPC: Seastar runs on a single machine, but many Seastar applications, including the Scylla distributed database which we use for the “Cloud Bursting” use case, offer a distributed service and therefore need convenient primitives for communicating between different machines running the same application. So Seastar offers RPC capabilities, with which the application running on one machine can call a normal-looking function returning a future value, while the Seastar seamlessly communicates with the remote machine, runs the function there, retrieves the result, and resolves the previously-returned future with that result. Seastar’s RPC also includes advanced features typically needed by distributed applications, such as serialization of data, negotiation (allowing different versions of the application to communicate with each other) and compression.
- Seastar threads: Those are not actual OS-level threads, but rather a mechanism to allow thread-like programming in Seastar: Code running in a “Seastar thread” has a stack like in normal threads; it can wait for a future to become resolved (by calling its get() method), and when the future resolves, the code continues to run from where it left off. The main overhead of Seastar threads compared to regular continuations is the memory taken up by the stacks, so we normally use Seastar threads for pieces of code where we have tight control over the number of times they run in parallel.
- System calls: In some cases, a Seastar application cannot avoid making a blocking system call. For example, to delete a file the unlink() system call must be used - Linux (or OSv) do not provide an asynchronous version of this system call. But Seastar application code must never block, as this can block the single reactor thread running on this core, and leave it idle. Therefore Seastar provides a mechanism of “converting” a blocking system call to a regular Seastar future. This is implemented by having a separate pool of threads dedicated to running the blocking system calls (and those threads will indeed block). Because these system calls are not frequently needed, the thread-based implementation does not negatively impact the performance of the application.
- Various utility functions: Seastar provides a large number of utility functions for making future-based programming more approachable. It has support for loops and iterations, semaphores (for limiting the number of times that a particular continuation may run in parallel), gates (for ensuring that all code related to some service completes before the service is shut down), pipes, input and output streams, and more.
- Asynchronous file I/O on buggy filesystems: we already mentioned AIO above, but there is an extra complication: Some filesystems - such as the popular ext4 on Linux - have buggy support for asynchronous I/O. The key requirement of asynchronous I/O is that such calls never block - they must always return immediately, and let the caller know later when the operation completed. Yet, on Linux ext4, some operations do block - e.g., while a file’s size is being extended and new blocks need to be allocated. This is clearly a bug in Linux, but one which Seastar had to work around. The solution involves knowing which operations do block, and avoid them or make sure they rarely happen and run them in the syscall thread pool. With these fixes, Seastar provides a true asynchronous experience even on ext4.
- Exception handling: Seastar futures can resolve to either a value (we provide an example in the next section) or an Seastar provides various mechanisms for handling exceptions which happen asynchronously, and should abort a chain of continuations, be handled, or both. We also made a significant effort to ensure that exception handling is efficient, but because of locks used by current implementations of the compiler, they should not be overused.
- Object lifetime management: Asynchronous applications need to worry about object lifetime management - e.g., an object which was created for the needs of a particular request, must be kept alive during the handling of this request (otherwise, we will crash), but must be destroyed when the request completes (or we’ll have a memory leak). Seastar provides various tools for object lifetime management, including optimized implementation of shared_ptr (to not use atomic operations, because thread-safety is not needed by Seastar applications), a do_with() function for ensuring that an object lives until a future is resolved, temporary_buffer for moving around temporary data which is automatically freed when no longer needed, and more.
- HTTP server: Seastar includes an HTTP server implementation (written, of course, in Seastar), which can be used by the application for various things - e.g., implementing a REST API.
- Logger, metrics and monitoring: Seastar also includes mechanisms for logging messages and errors, and collecting metrics (counters, sums, etc.), and for reporting them to various collection mechanisms such as Collectd or Prometheus - and through them also to MIKELANGELO’s Snap.
[[i]] Kivity, A. et al. OSv—Optimizing the Operating System for Virtual Machines. In Proceedings of USENIX ATC’14: 2014 USENIX Annual Technical Conference (p. 61).
[[ii]] Memcached homepage, http://docs.libmemcached.org/bin/memaslap.html
[[iii]] Seastar homepage http://seastar-project.org/
[[iv]] ScyllaDB benchmarks, http://www.scylladb.com/product/benchmarks/
