![]()
MIKELANGELO has adopted, extended and enhanced Intel’s snap open-source telemetry framework to deliver full-stack instrumentation and monitoring across all of the MIKELANGELO use cases.
Snap is a framework that allows data center owners to dynamically instrument cloud-scale data centers. Precise, custom, complex flows of telemetry can be easily constructed and managed. Data can be captured from hardware and software sources, in-band or out-of-band, local or remote, periodically or event-based, via snap collector plugins. Captured data can be passed through local filters - snap processor plugins - that analyse and perform some action on the data. The processed data can then be published by snap publisher plugins to arbitrary destinations. Endpoints can include SQL and NoSQL databases, file-systems, and message queues.
Snap has been developed from the ground up to be trustworthy, performant, dynamic, scalable and highly extensible. Snap includes:
- a daemon on nodes that collect, process and/or publish data. The data can be collected from the local node, or from remote nodes.
- a dynamic catalogue of metrics, based on currently loaded plugins
- highly configurable telemetry workflows, knowns as tasks
- a command line interface that allows metrics, plugins and tasks to be manipulated
- a RESTful API for remote management
- simplified cluster-aware management via tribe
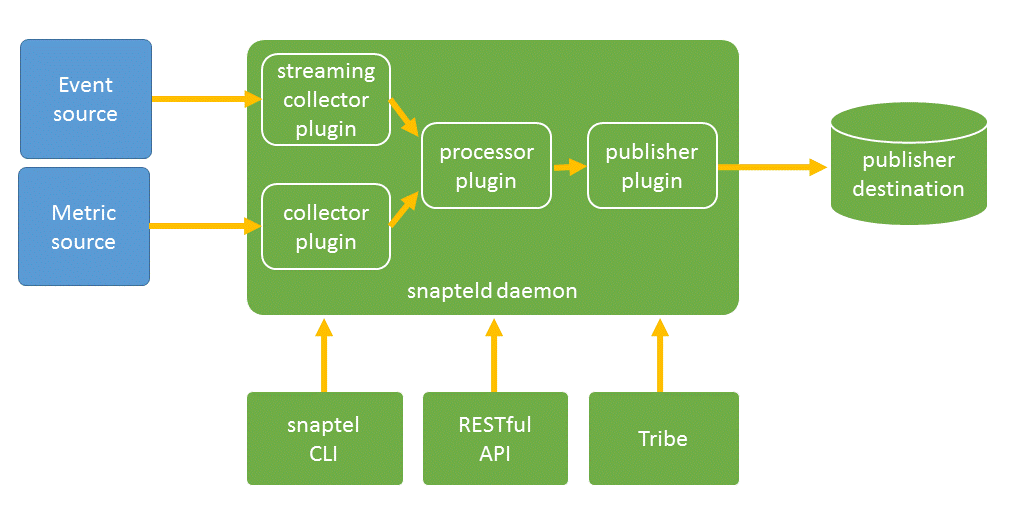
Core components of Snap
For a complete introduction to snap in MIKELANGELO see our blog post “Full-stack cloud-scale instrumentation? It’s a snap…“.
Achievements and Results
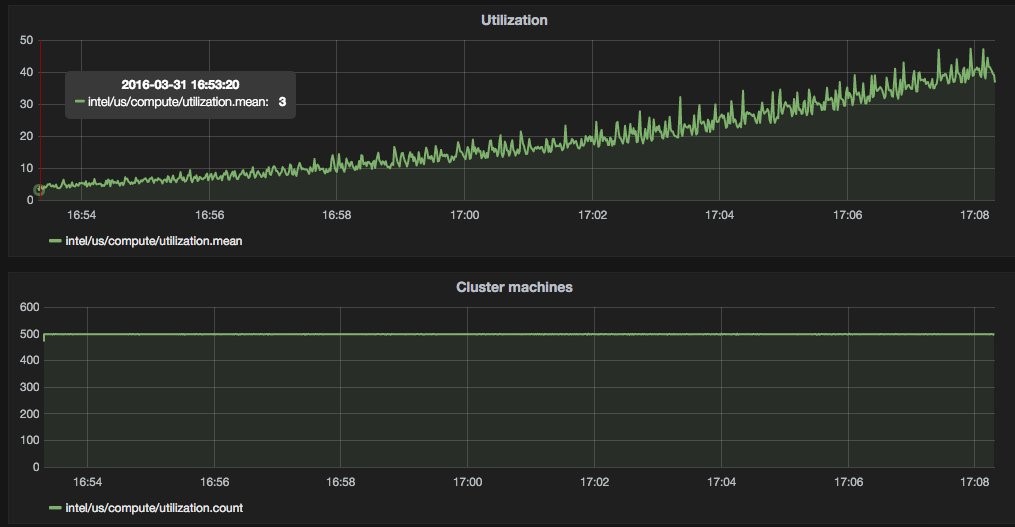
Snap capturing CPU utilisation from a 500 node cluster (click to expand)
MIKELANGELO has developed and open-sourced plugins to
- collect data from Libvirt, OSv, MongoDB, SCSI, OpenFOAM, yarn, schedstat, Open vSwitch, and KVM,
- aggregate Utilisation, Saturation and Errors data from compute, storage, memory, network subsystems,
- inject meta-data tags to facilitate offline analysis,
- dynamically reduce telemetry resolution when data is stable - reducing network traffic by factor of 16 in one deployment, without affecting statistical insight
- publish telemetry to PostgreSQL.
MIKELANGELO has also demonstrated snap running on a 500 node cluster, and proven that the MIKELANGELO-enhanced ScyllaDB rewrite of Apache Cassandra can be employed as a back-end data-store for snap-gathered telemetry.
Snap can already collect data from OpenStack Cinder, Glance, Keystone, Neutron and Nova.
MIKELANGELO developed and open-sourced software that automates provisioning and configuration management of the Snap framework and plugins: snap-deploy. MIKELANGELO has also contributed to broader snap enhancements including plugin diagnostics, streaming collectors, and Swagger-based APIs.
Here are pointers to key snap resources from both our project and the community that you may find useful. Enjoy!
MIKELANGELO Resources
Reports
- D5.7 First report on the Instrumentation and Monitoring of the complete MIKELANGELO software stack - published January 2016. Introduces the monitoring requirements of MIKELANGELO, the state-of-the-art, the adoption of snap by the project, and our contributions by the end of 2015.
- D6.1 First report on the Architecture and Implementation Evaluation - published July 2016. Section 2.6 includes an evaluation of the snap framework in MIKELANGELO from architectural, performance and implementation points of view.
- D5.2 Intermediate report on the Integration of sKVM and OSv with Cloud and HPC - published January 2017. Section 3.1 details the plugins developed since the publication of D5.7.
- D2.21 The Final MIKELANGELO Architecture - published July 2017. Section 8 describes the final architecture for the snap implementation in MIKELANGELO.
- D5.3 Final report on the integration of sKVM and OSv with Cloud and HPC - published January 2018. Section 3.1 details the snap enhancements since the publication of D5.2.
- D6.2 Final report on the Architecture and Implementation Evaluation - published January 2018. Section 2.8 includes an updated evaluation of the snap framework from an architectural, performance and implementation points of view.
Presentations
- Cloud Telemetry - Monitoring the Performance of the Cloud at Linux Fest 2017. Page includes slides and video with audio.
- Anomaly Detection in Go was presented by Marcin at GopherCon 2017.
Blog Posts
- Full-stack cloud-scale instrumentation? It’s a snap… - published July 2016. Introduces snap in MIKELANGELO, summarising all contributions to snap to date, contributions that are imminent, and results of integration work between snap and ScyllaDB.
Software Releases
- snap collector plugins
- snap processor plugins
- snap publisher plugins
- snap utilities
Community Resources
- snap home page - start here!
- snap on GitHub - get all the code, log suggestions, contribute
- snap blog posts - technical insights and articles to get you up and running
- snap team on slack - chat with snap developers
- snap videos - hear the thinking behind snap, see snap in action, and watch some how-to’s.
- snap tutorial - detailed instructions on installing and using snap
