Introduction
Over the course of the MIKELANGELO project, different attempts have been made to improve the performance of applications running inside OSv operating system. In the context of this work, shorter latency and higher throughput are the main metrics of the network performance. MIKELANGELO project has already made significant improvements in supporting functional requirements of the workloads running in OSv. This has been demonstrated by the Cancellous bones and Aerodynamics use cases that have been successfully executed in OSv early in the project. On the other hand, OSv is still lacking performance improvements that would allow it to be used in the high performance computing domain. One of its most limiting factors is its inability to interpret and use NUMA (Non-uniform Memory Access) of modern processors. Because OSv equally treats memory from different NUMA domains, it is unable to optimise CPU and memory pinning the way general purpose operating systems do.
One way of addressing this problem is the adoption of Seastar framework that handles CPU and memory pinning internally and properly handles this limitation. However, this requires a complete rewrite of the application logic which is typically impractical or even impossible for large HPC simulation code bases. To this end, this section introduces a novel communication path for colocated virtual machines, i.e. VMs running on the same physical host. With the support of the hypervisor (KVM) the operating system (OSv) is able to choose the optimal communication path between a pair of VMs. The default mode of operation is to use the standard TCP/IP network stack. However, when VMs residing on the same host start communicating, standard TCP/IP stack is replaced with direct access to the shared memory pool initialised by the hypervisor. This will allow the cloud and HPC management layer to distribute VMs optimally between NUMA nodes. This section explains in detail the design and the findings based on the prototype implementation.
Another driver for investigating addition approach to optimising intra-host communication is the raise of so called serverless operations. Serverless architectures are becoming widely adopted by all major public cloud providers (Amazon, Google and Microsoft) in a form of so called cloud functions (Amazon Lambda, Google Cloud Functions and Azure Cloud Functions). This has been made possible with the tremendous technical advances in the container technology and container management layer planes. Cloud functions are stateless services communicating with each other and other application components over established channels using standard APIs and contracts. The very nature of these services allows for seamless optimisation of workloads, service placement management and reuse, as well as fine-grained control over the billable metrics in the infrastructure.
OSv-based unikernels are ideal for the implementation of such serverless architectures because they are extremely lightweight, boot extremely fast and support running most of the existing workloads, i.e. they mimic the advantages of containers. All the benefits of the hypervisor are furthermore preserved (for example, support for live migration, high security, etc.). In light of the aforementioned facts, optimising the networking stack for collocated unikernels will allow for an even better resource utilisation because the interrelated services will be able to bypass the complete network stack when sharing data between each other.
Background
The serverless operations described in the introduction are an extreme example of separating large monolithic applications into smaller services specialising for specific business logic. Even when not targeting serverless deployments, modern applications are typically split into multiple weakly coupled services, which communicate via IP network. Figure 1 presents typical communication paths used by applications running inside virtual machines. In this case, the server application, e.g., database, is running in VM-1, while client applications, e.g., data processing services, run in VM-2 and VM-3. Virtual machines VM-1 and VM-2 are collocated on the same, while VM-3 is placed on a different host.
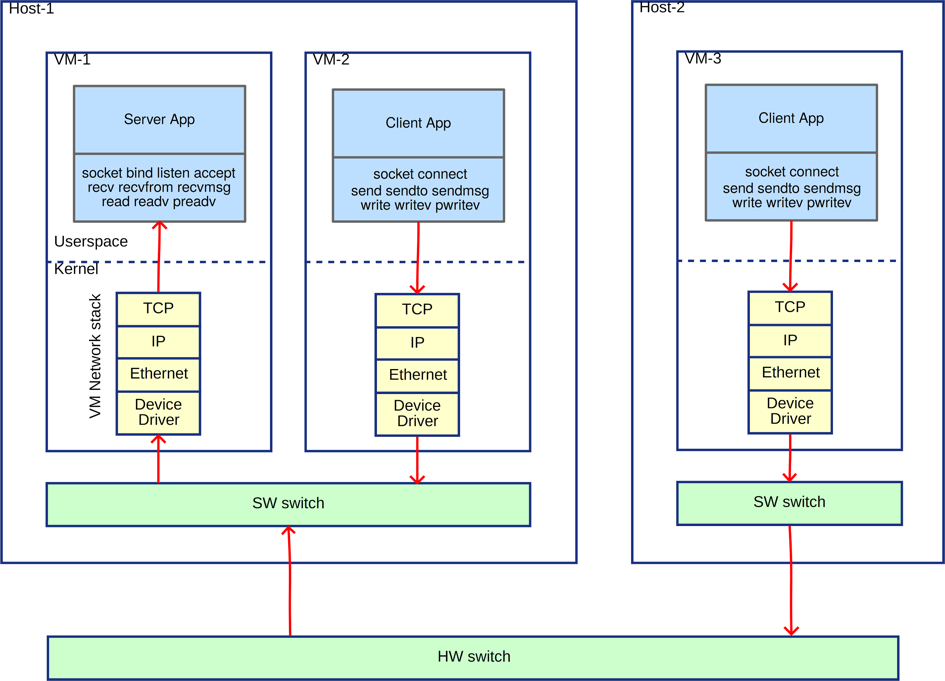
Figure 1. Traditional communication paths used by applications running inside virtual machines
When client application (VM-3) runs on a different host than server application (VM-1) data traverses many layers. First, the data goes through the entire network stack of the guest operating system and sent to the software switch in the client virtualization host. From there, the packet is sent to the physical network. On the other side, the virtualization host of the server receives the packet from the physical network and forwards it to the software switch. The packet finally goes through Server’s network stack and is delivered to the server application.
When server and client machines are collocated on the same virtualization host (VM-2 and VM-1), the whole process is greatly simplified. In this case, the physical network in not used because the virtual switch in the host automatically detects collocated virtual machine and delivers the packet directly into the network stack of the target VM. This allows higher throughput at lower resource usage.
UNCLOT component of MIKELANGELO was implemented to further improve the latter case, i.e. the intra-host TCP/IP-based communication by eliminating most of the IP processing. This is particularly important because the TCP protocol was designed on top of unreliable, lossy, packet-based network. As such it implements retransmission on errors, acknowledge and automatic window scaling in order to guarantee reliable and lossless data stream. However, it is safe to assume that communication between collocated VMs is highly reliable.
To eliminate most of the aforementioned processing overhead of the network stack we implemented TCP/IP like communication based on shared memory. Instead of sending actual IP packets via software switch, the source VM puts data into memory shared between VMs on the same host. Target VM can then directly access the data. Multiple approaches to bypassing network stack have been analysed by Ren et. al.[i]. The approaches are classified according to the layer of the network stack at which the bypass is built into. In general, the higher in the application/network stack the bypass is implemented higher throughput and lower latency can be achieved because more layers of the networking stack are avoided. On the other hand, the higher the layer at which the bypass is implemented, the less transparency is preserved. For example, replacing all send() system calls with a simple memcpy() will result in the fast communication between two VMs. However, this performance benefit will result in significant additional constraints for the said application. It will require that every part of the application that needs to communicate with other VMs makes a change in the source code. Furthermore, it will prevent distributed deployment of such application because of memory-only communication. This thus requires additional development and debugging effort for each application which should benefit from modifications.
Implementation Details
UNCLOT relies on the standard network socket API implementation of OSv operating system. It adds a separate communication path that uses shared memory provided by the KVM/QEMU hypervisor in order to support complete bypass of the TCP/IP network stack when communication occurs between two collocated VMs. Inter-VM communication therefore uses IVSHMEM component. IVSHMEM shared memory is supported in mainline QEMU, and is exposed to VM as a PCI device. Hence we first needed to develop a device driver for IVSHMEM PCI device for OSv.
The implementation of this bypass requires changes in the OSv implementation ensuring that standard functions like socket(), bind(), listen(), connect(), send(), recv() are reimplemented in order to support shared memory as a communication backend.
The following diagram shows a high-level design. Neither server nor client application need to know about the change in the communication channel. The aforementioned API functions transparently choose either standard network stack or shared memory depending on the IP address of packet’s destination.
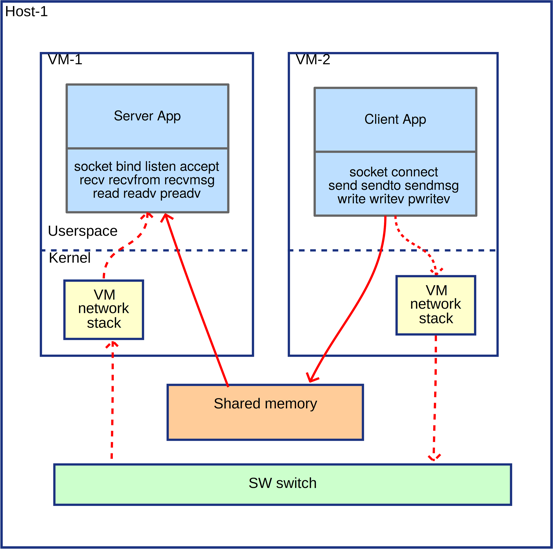 Figure 2. High-level architecture of UNCLOT.
Figure 2. High-level architecture of UNCLOT.
Using shared memory as a single large block of memory is rather difficult and error prone. It is more user friendly if arbitrary sized chunks of data can be allocated on demand. When shared memory is used in a standard Linux application, the System V shared memory interface (http://www.tldp.org/LDP/lpg/node21.html) is one of most commonly used interfaces. A similar interface for allocation of memory chunks from IVSHMEM device was therefore implemented in OSv.
When multiple VMs need to allocate memory from the same IVSHMEM device at the same time, synchronization is required to prevent data corruption. Some care is required as usual OSv synchronization primitives (i.e. mutex class) are only applicable within a single address space of one virtual machine instance and cannot be used across many VMs. Thus the first step was to implement a dedicated lock class, suitable for use from multiple VMs. This lock ensures stable and synchronized allocation of new memory chunks from an arbitrary VM running on the same host.
Allocated memory chunks are used to hold in-flight TCP data - e.g. as a send or receive buffer. Each TCP connection requires two memory chunks for proper operation. One is used as the send and the other as the receive buffer. The allocated memory chunk is managed as a circular ring buffer. This way the same memory chunk can be reused continuously. When the end of the buffer is reached, it continues at the beginning. Because that data has already been read and processed, this approach does not corrupt the transfer of the data.
TCP connections are uniquely identified by source IP, source port, destination IP and destination port. In case of collocated VMs where shared memory can be used, special logic needs to be built into the networking logic. When data is sent, the network socket file descriptor needs to be converted into the corresponding circular ring buffer. After this, the data is written into the ring buffer instead of the corresponding network socket. In a similar way data needs to be read from a corresponding ring buffer instead of from the network socket. A utility class sock_info has been implemented to maintain relationships between the TCP connection source IP, source port, destination IP, destination port, file descriptor and the send/receive ring buffer. Lookup functions are provided to find correct the ring buffer based on source/destination IP/port or based on file descriptor.
Performance Evaluation
During the evaluation we focused primarily on comparing unmodified OSv against OSv with UNCLOT enabled. Two synthetic benchmarks were used to analyse the improvements and limitations of UNCLOT:
- OSU Micro-Benchmarks is a suite of benchmarks used to analyse the performance of MPI standard implementations.
- Nginx server with wrk workload generator is used to measure performance of UNCLOT-enabled HTTP communication.
Figure 3 shows the bandwidth of running OSU Micro-Benchmark. Three scenarios are considered. The ideal case represents a case where the benchmark is executed in a single OSv instance, thus using optimal communication path between MPI workers. OSv with TCP/IP represents a case where two instances running unmodified OSv kernel on the same host. Standard TCP/IP networking is used. OSv with UNCLOT also uses two OSv instances, but enables UNCLOT to exchange messages between MPI workers. Even though the ideal case outperforms both other scenarios, UNCLOT shows an improvement, in particular when message size is larger than 1024 bytes. The bandwidth of UNCLOT constantly outperforms unmodified OSv by a factor of 3-6.
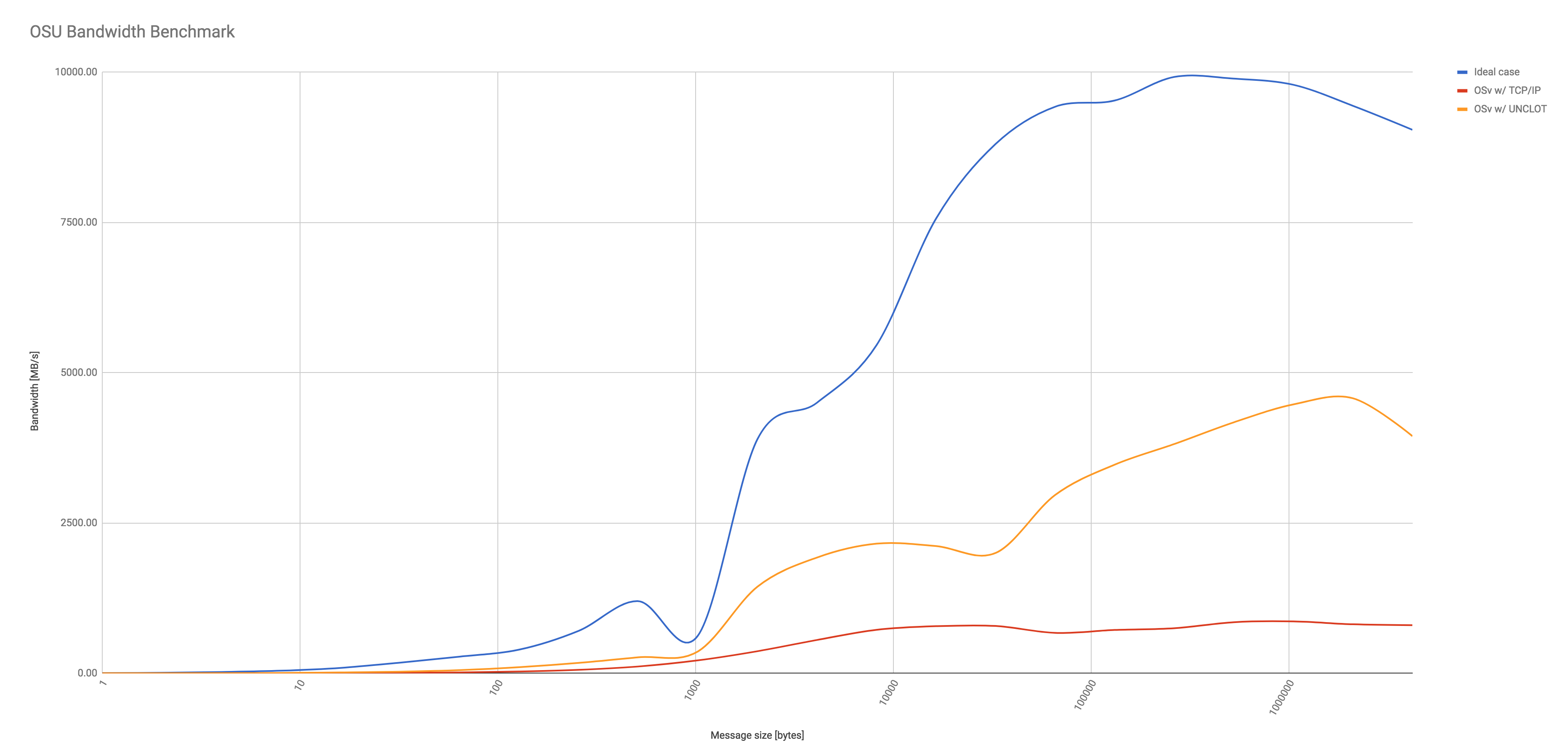
Figure 3. OSU Micro-Benchmarks bandwidth test.
Latency benchmarks shown in Figures 4 show that UNCLOT furthermore reduces the latency by a factor of between 2.5 (larger messages) and 5 (smaller messages). Similar to the bandwidth, the ideal case where workers are running in the same OSv instance clearly outperforms UNCLOT.
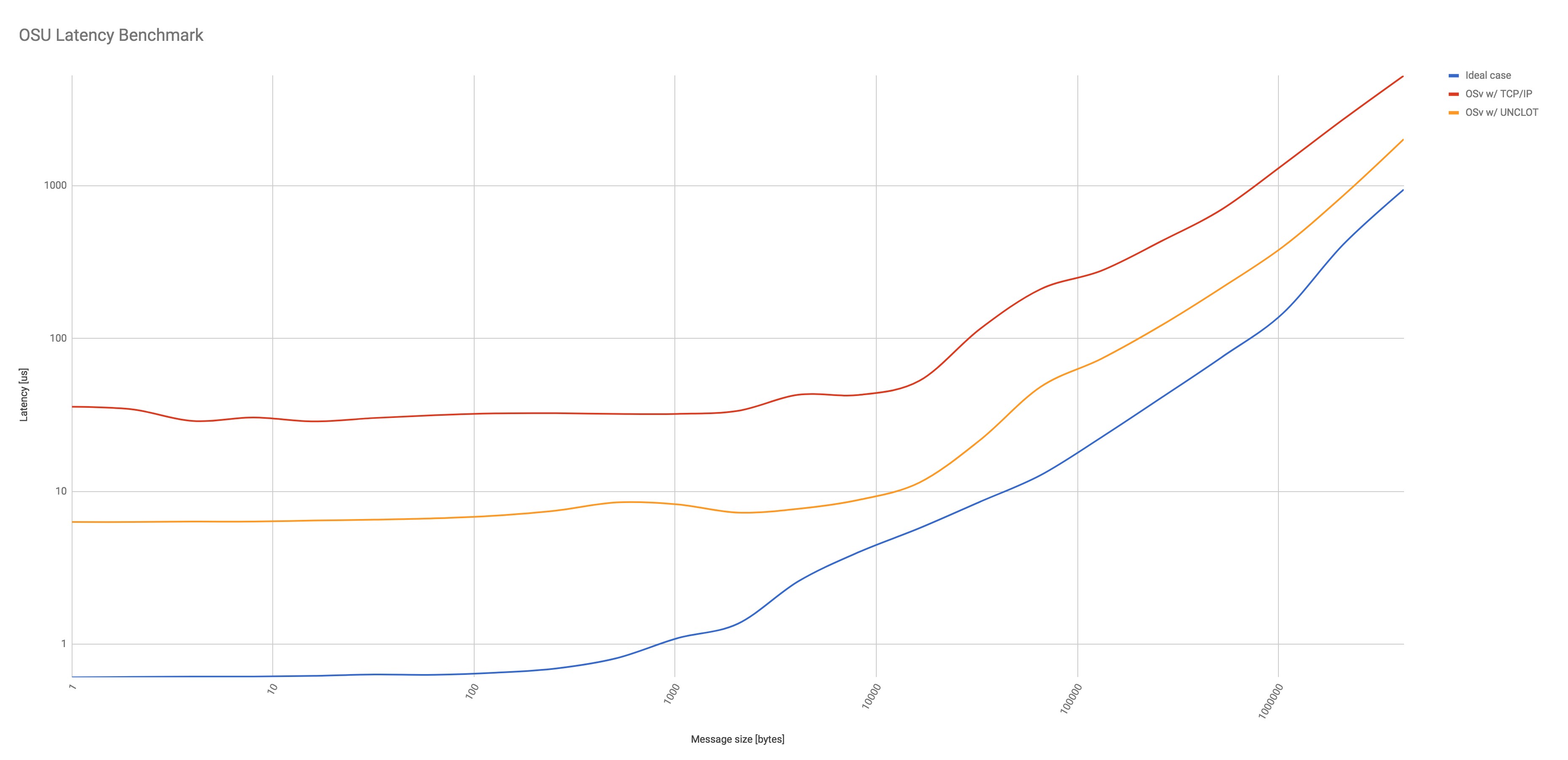
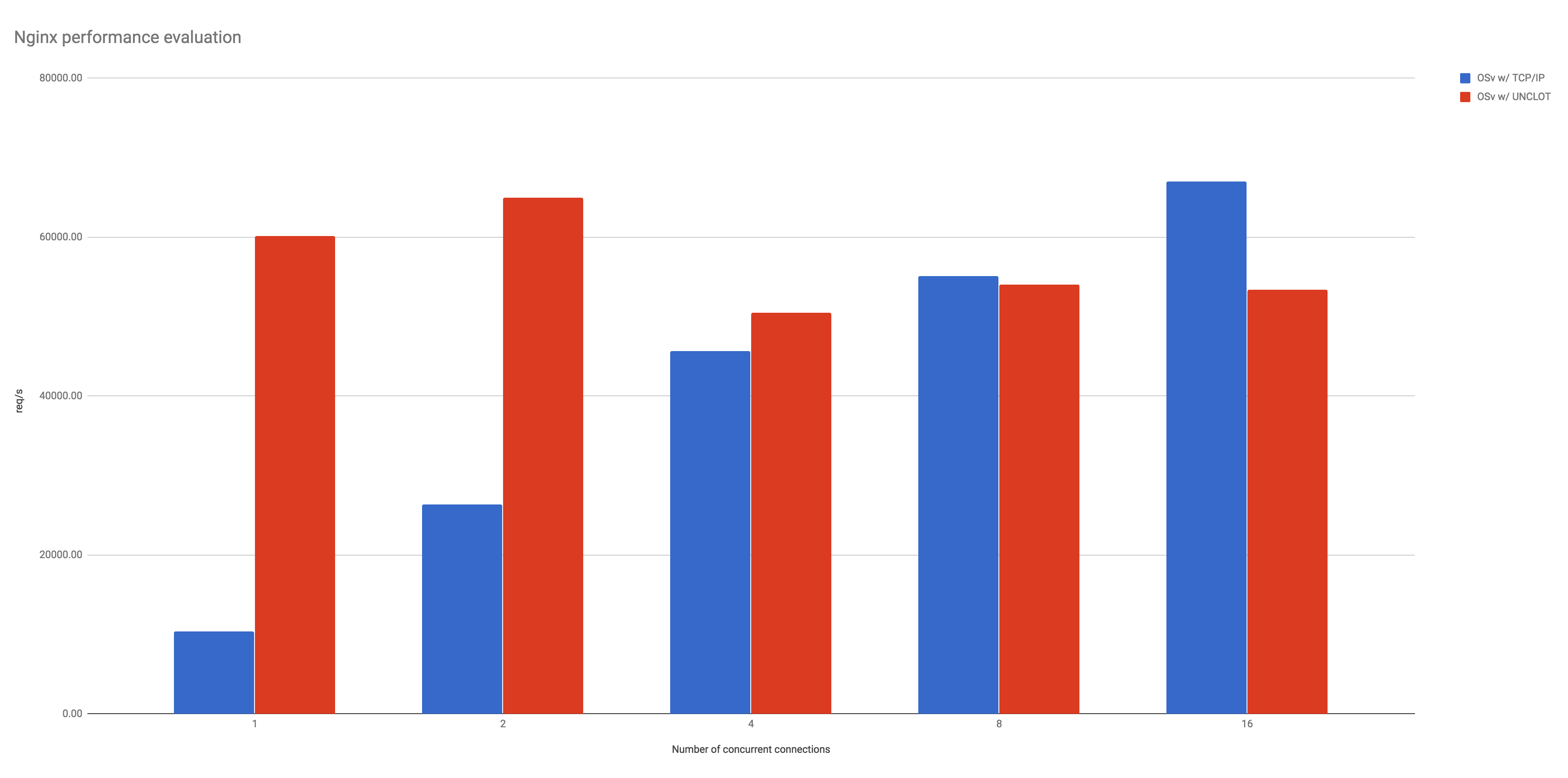
The final benchmark evaluates UNCLOT using Nginx HTTP server serving simple static page to a wrk workload generator, depending on the number of concurrent connections, i.e. sockets. This evaluation clearly shows the theoretical improvement UNCLOT can deliver in case of one or two active sockets and indicates a limitation of the current implementation. It is assumed that performance deterioration is attributed to the way communication is synchronised in this proof of concept (through a busy wait loop).
More in-depth technical details in the final report on the hypervisor implementation: D3.3 - Super KVM - Fast virtual I/O hypervisor.
References
[i] Yi Ren, Ling Liu, Qi Zhang, Qingbo Wu, Jianbo Guan, Jinzhu Kong, Huadong Dai, and Lisong Shao. 2016. Shared-memory optimizations for inter virtual machine communication. ACM Comput. Surv. 48, 4, Article 49 (February 2016), 42 pages. http://www.cc.gatech.edu/grads/q/qzhang90/docs/YiRen-CSUR.pdf
[ii] Open MPI Shared Memory BTL, https://www.open-mpi.org/faq/?category=sm.
[iii] https://github.com/qemu/qemu/blob/master/docs/specs/ivshmem-spec.txt
[iv] Nagle’s algorithm, https://en.wikipedia.org/wiki/Nagle%27s_algorithm
[v] Iperf tool, https://iperf.fr
[vi] Netperf tool, https://linux.die.net/man/1/netperf
[vii] Apache bench tool, http://httpd.apache.org/docs/current/programs/ab.html
