OpenFOAM aerodynamic use case
This blog post describes how a complete Apache Spark application can be deployed on Kubernetes. Figure 1 illustrates the deployment: it contains a single Docker container (Spark Driver) and two kinds of OSv unikernels, the Spark Master and the Spark Workers. The complete setup is available in mikelangelo-project/osv-spark-demo GitHub repository and can be deployed with a single command (assuming that Kubernetes cluster is up-and-running and has Virtlet runtime installed):
$ kubectl create -f virtlet_deploy/spark.yaml
The command above will deploy the following components to a Kubernetes cluster:
- “spark-master” Deployment (with a single replica)
- “spark-master.default” Service
- “spark-worker” Deployment (with two replicas)
- “spark-driver” Deployment (with single replica)
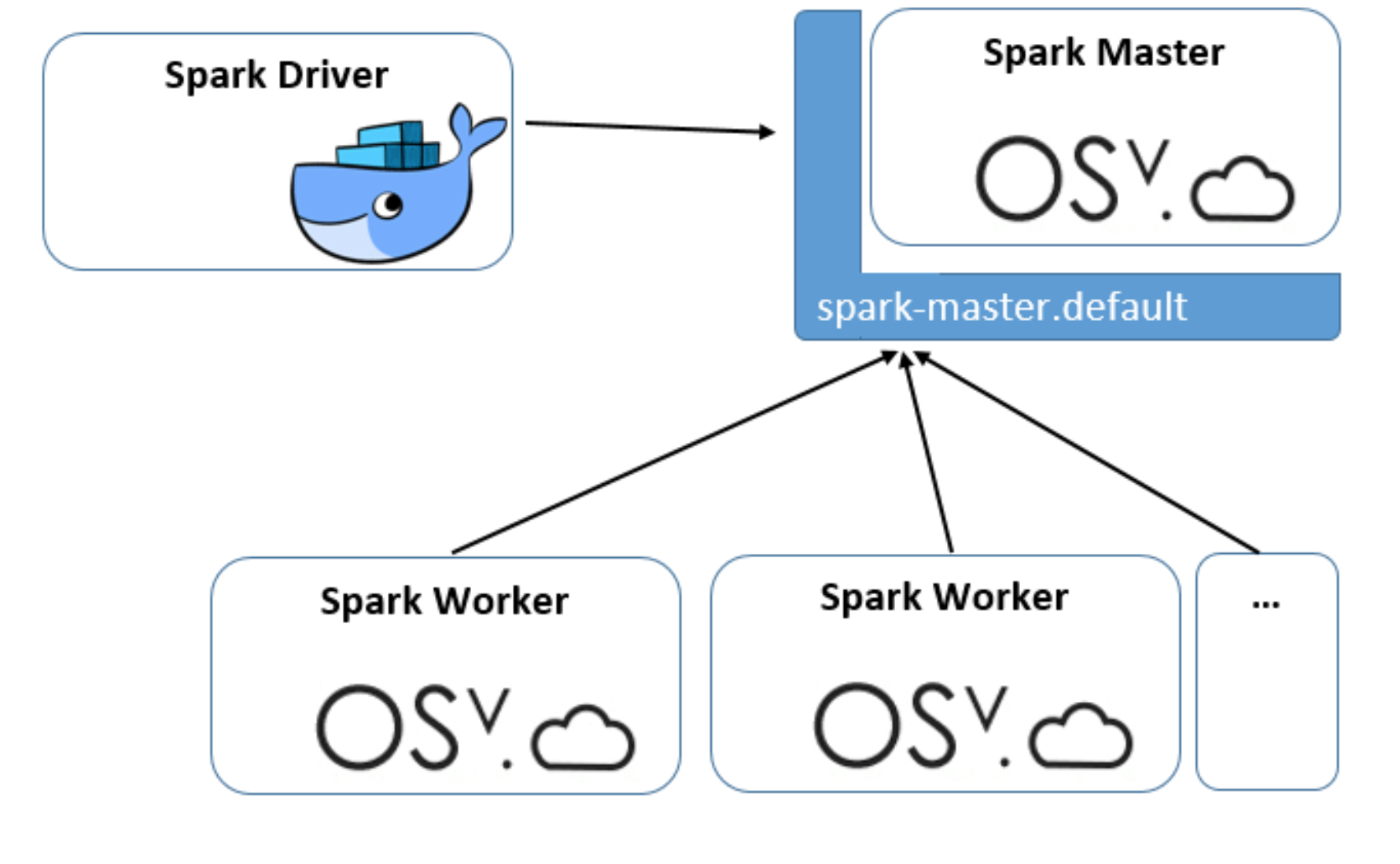
Figure 1: Apache Spark deployment on Kubernetes.
Spark Master. An OSv unikernel image with the two packages osv.cloud-init and apache.spark-2.1.1 is used and the boot command set to sleep forever. Total size of the unikernel image is 192 MB. Unikernel is given a command to run Spark Master via Virtlet’s cloud-init mechanism when provisioned, as can be seen in its Deployment specification:
annotations: kubernetes.io/target-runtime: virtlet.cloud VirtletDiskDriver: virtio VirtletCloudInitUserDataScript: | run: - POST: /env/PORT val: 7077 - POST: /env/UIPORT val: 8888 - PUT: /app/ command: "runscript /run/master"
The cloud-init script first sets two environment variables, PORT and UIPORT, that are then consumed by /run/master run configuration. The master run configuration is defined within apache.spark-2.1.1 package as:
runtime: native
config_set:
master:
bootcmd: >
/java.so
-Xms$XMS
-Xmx$XMX
-cp /spark/conf:/spark/jars/*
-Dscala.usejavacp=true
org.apache.spark.deploy.master.Master
--host $HOST
--port $PORT
--webui-port $UIPORT
env:
XMS: 512m
XMX: 512m
HOST: 0.0.0.0
PORT: 7077
UIPORT: 8080
One can notice how the user actually doesn’t need to provide the exact command in the cloud-init, but can make use of pre-prepared run configurations that are provided within packages. By specifying PORT and UIPORT environment variables in the cloud-init above we only customize the bit that we need to customize.
Spark Master is proxied with a Service to make it addressable as “spark-master.default” from within Kubernetes cluster so that other workloads (Workers and Driver) don’t deal with mutable IP address.
Spark Worker. An OSv unikernel image equal to that of a Spark Master is used to run Spark Worker, only cloud-init invokes a different run configuration in it, as can be seen in its Deployment yaml specification:
annotations:
kubernetes.io/target-runtime: virtlet.cloud
VirtletDiskDriver: virtio
VirtletCloudInitUserDataScript: |
run:
- POST: /env/MASTER
val: spark-master.default:7077
- PUT: /app/
command: "runscript /run/worker"
An environment variable MASTER is first set to “spark-master.default:7077” and is then consumed by the worker’s runscript that runs the Apache Spark worker thread which automatically registers itself to the Master address. Two Worker replicas are deployed by default, but the number can easily be increased at any time.
Spark Driver. A third-party Debian based Docker image with preinstalled Spark & Hadoop distribution is used as a base for the mikelangelo/spark-driver image and then some additional utility software is added to support the demo. The sole purpose of this container is to submit the Spark job to the Spark Master. Total size of the container is 460 MB.
To run the demo one needs to execute the following command on their host computer (assuming that containers and unikernels are already deployed):
$ ./demo.sh
The script will remotely execute a Spark submit command inside the Driver container. A demo application will be submitted that runs 1000 tasks to calculate PI decimals. The calculation result, i.e. PI estimate, is printed to the console.
Related posts



Pingback: Virtlet: run VMs as Kubernetes pods | Mirantis - fringopost()