MIKELANGELO at Linux Plumbers Conference 2017 in Los Angeles

In this article, we tell you how the MIKELANGELO project aims to improve the I/O performance of virtual machines. The inability of virtual machines to run HPC and big data applications in production due to low I/O performance motivates our work. Read on to learn why we want to improve the performance of virtual machines, how we plan to do it, and what the community has to say on the topic.
Introducing: sKVM
In MIKELANGELO, we build on KVM, a widely used open source hypervisor. Our work will result in sKVM, a version of KVM optimized for I/O workloads.
During the last few years, data center operators have begun to use virtual machines to provision servers. The benefits of using virtual machines over physical hosts comprise resource consolidation and convenient high-level management of services. These features allow you to save money and provide more robust services. Typical services that run in virtual environments are web services, enterprise systems, and increasingly also network functions (NFV).
Host virtualization grew into cloud computing by adding management layers for convenience. Thus, cloud computing leverages virtualization to provide simplified management of servers. When you set up a cloud on-premise you probably use OpenStack, the most popular open-source cloud middleware. In turn, OpenStack interfaces primarily with KVM as a hypervisor. Thus, in the wild, many services leverage the power of KVM to reap the benefits of cloud computing. Because of OpenStack’s popularity and because it builds on KVM, which in turn is open source software, we prefer KVM as a hypervisor over its numerous alternatives.
Despite its wide-spread adoption, cloud computing has two important blemishes: HPC and big data. These popular types of applications would benefit from the flexibility of the cloud, but still do not even use virtualization. Because they often feature I/O-intensive workloads, both types of applications have not found their way to virtual infrastructures yet.
Although CPU-bound workloads reach near-native performance in virtual machines, I/O-bound operations incur a significant overhead with KVM. At the same time, both HPC and big data require top performance. Thus far, data center operators choose the performance of native deployments over the management features of the cloud.
We want you to have both: the flexibility of the cloud and nearly the performance of native deployments. That’s why we are developing sKVM.
The Shortcomings of KVM for I/O-intensive Workloads
To obtain a baseline of KVM’s performance for I/O-heavy workloads, we ran benchmarks. These benchmarks show the shortcomings of KVM for I/O-intensive applications. Here, we briefly mention the results of two benchmarks, HiBench and netperf.
The first illustration below shows how several big data workloads in HiBench run longer when using virtual machines instead of a physical host. Particularly, the I/O-intensive workloads’ performance suffers. If you run a big data application and you have to wait three times longer than usual you will probably get annoyed.
The second illustration shows the speedup recorded with a prototype of sKVM in contrast to KVM when running netperf with various message sizes. There you can see that our prototype already performs nearly twice as fast as KVM for some cases!
You can dig into the details on the experiments with HiBench, netperf and other benchmarks in our respective reports.
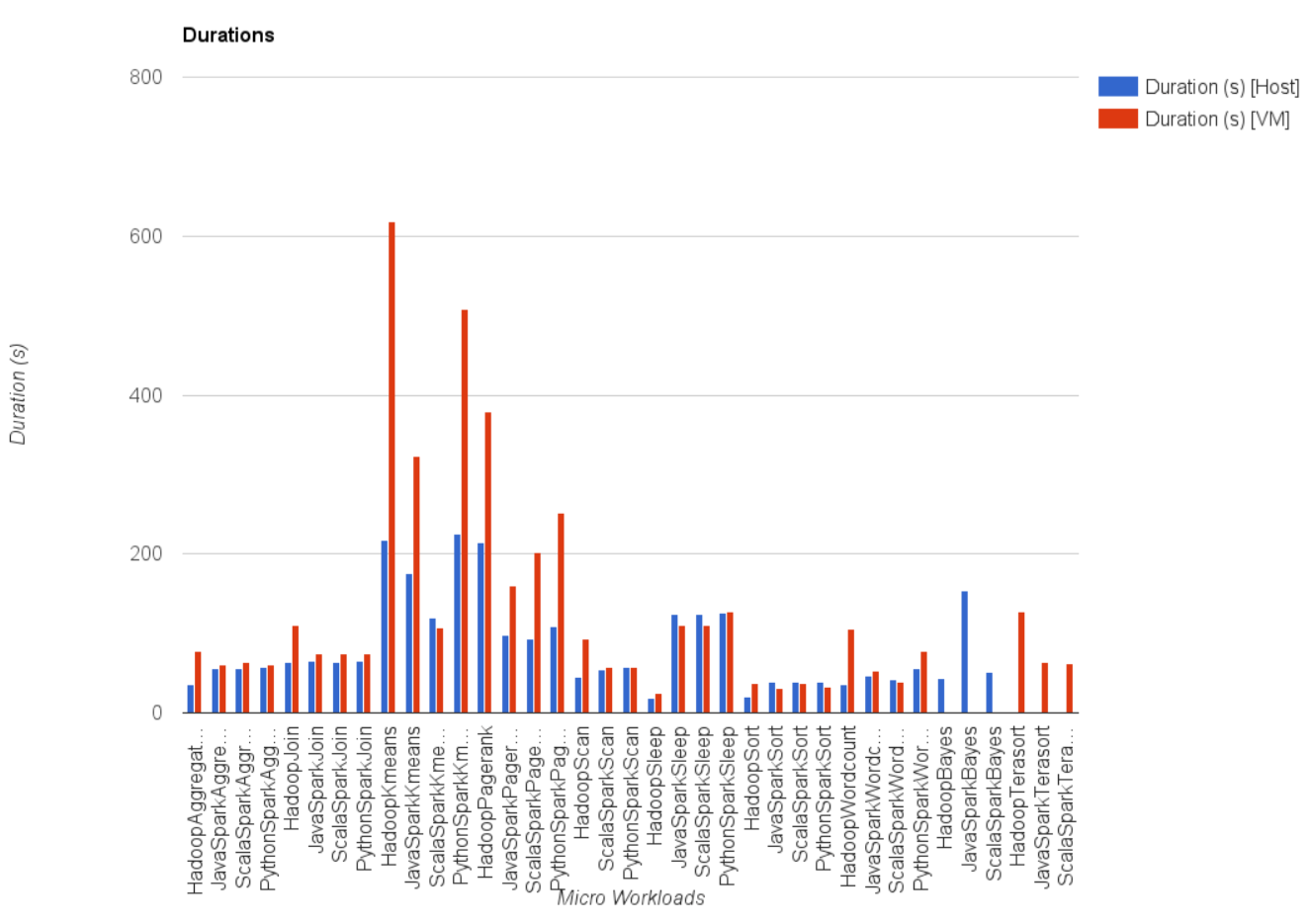
Comparison of the performance of big data benchmarks between VMs and native deployment.
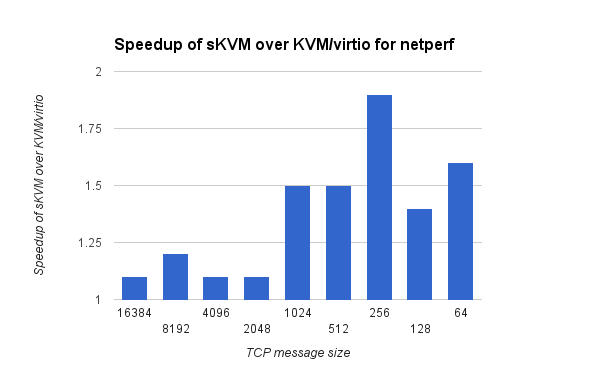
Speedup achieved by a prototype of sKVM over KVM and virtio
Currently, if you wish to improve I/O performance in KVM you can switch to a para-virtualized I/O driver called vhost. With vhost, the I/O device driver within the guest system uses the virtio protocol to communicate with the vhost driver running within the hypervisor. This combination of the guest I/O device driver and vhost in the hypervisor performs much better than the default driver. However, we can still improve the performance of vhost.
With sKVM we want to surpass the I/O performance of KVM and vhost.
Approaches to Improve KVM’s I/O Performance
We have identified four related approaches to improve I/O performance in KVM. These approaches build on the observation that context switches between the guest and the host introduce significant CPU overhead for each VM while handling I/O-intensive workloads.
In sKVM, we introduce four enhancements over KVM to address this inefficiency:
- ability to run the host threads serving the virtual machine’s I/O devices on dedicated CPU cores, as opposed to the standard approach of running vCPU threads and I/O threads on the same set of cores,
- ability to serve multiple I/O devices of VMs by a shared vhost thread, as opposed to the standard approach of having a separate vhost thread for each virtual I/O device,
- ability to use physical device polling instead of interrupts during I/O-intensive periods,
- ability to dynamically manage and optimize the configuration of #1 - #3 above, based on dynamic metrics collected at runtime.
We expect that these approaches will improve the I/O performance in sKVM significantly.
However, just implementing these features will not speed up “the cloud”. We have to make sure you can use theses features seamlessly. Thus, we aim at early contribution of the code upstream, primarily targeting the vhost module of KVM, which is part of Linux. As a first milestone we have presented our ideas and findings at the KVM Forum 2015.
Insightful Discussions at the KVM Forum
We have presented our ideas at the KVM Forum, which is the primary conference for all things KVM.
As it often happens with open source communities, it does not suffice to have a great idea or even a prototype, to find the community’s acceptance. You need to socialize your idea and the implementation approach as early as possible. Such exchanges allow to solicit feedback and to come up with a staged approach to code contribution. To allow the community to review code and merge contributions upstream efficiently, the contributions are broken down into increments. Succeeding to contribute our results upstream will make the difference between producing a fringe product and an integral part of the standard cloud computing stack.
For KVM, developers discuss new contributions on the KVM development mailing list. However, the most important proposals are brought to the annual face-to-face conference of the KVM community: the KVM Forum.
Because the KVM Forum is the central event of the KVM community’s interaction, the conference selects the best proposals for topics in a competitive process. We were excited that our proposal to discuss the progress on our joint work between Red Hat and IBM was chosen as one topic. The event took place in Seattle, between August 19-21 2015.
Given the opportunity to receive direct and concrete feedback from the community, we narrowed down the discussion to the technical details of capability #2 above. We have presented how to share vhost threads among several I/O devices, which may belong to several VMs.
Our topic’s presentation by Bandan Das from Red Hat and Eyal Moscovici from IBM was well-received (see the video and slides).
The discussion produced valuable insights for us. For example, we learned about the alternatives to integrate the proposed shared vhost implementation with cgroups. The integration with cgroups will allow accounting of the resources used by vhost on behalf of the guest. For example, if vhost handles multiple virtual machines then cgroups will account the CPU cycles for each virtual machine separately. By extension, cgroups’ CPU modules will then enforce CPU allocation policies. One possible approach leverages the mechanism of work-queues and its future integration with cgroups.
The feedback at the KVM forum has shown us that we are on the right path to implement our ideas. Our new insights will increase the likelihood that you will get to use an open-source hypervisor with high I/O performance in your cloud soon.
Next Steps Towards sKVM
Now we will build on the feedback from the KVM forum and implement our ideas. Since we open-source our work you will get your hands on sKVM soon.
You can read more about our approaches to build sKVM in our latest project report. If you’re curious what MIKELANGELO offers on top of improved I/O performance with sKVM take a look at our other reports.
Related posts

Pingback: ()
Pingback: Making Torque ready for Virtual Machines - Mikelangelo - Horizon 2020 Project on Virtualization, Cloud Computing, and HPC()
Pingback: pharmacy intern()
Pingback: cialis online from canada()